

IBM 認證管理員 – 安全性 QRadar SIEM V7.5
認證概述
此中級認證適用於希望驗證其對 C1000-156 IBM Security QRadar SIEM V7.5 管理的全面了解的專業人士。
這些管理員將具備 IBM Security QRadar SIEM V7.5 本機部署的配置、效能最佳化、調優、故障排除和系統管理的知識和經驗。這包括與 QRadar 一起安裝的應用程式:使用案例管理器、QRadar Assistant、日誌來源管理器和 Pulse,以及對以下方面的基本了解:使用者行為分析、QRadar 部署智慧、參考資料管理。這不包括 SaaS 產品 QRadar on Cloud (QRoC)。
推薦技能
關鍵能力領域
QRadar 故障排除
搜尋和報告
規則和建構模組
了解參考資料
基本 QRadar 調整與網路層次結構
QRadar 部署和元件架構
了解 QRadar 事件和流管道
QRadar 使用者管理和資料存取控制
多域基本概念
QRadar 實例
預備知識(考試不衡量)
基本安全技術、SIEM 概念、TCP/IP 網路、IT 安全概念和 IT 技能
攻擊和日誌分析
企業日誌記錄
使用流量進行網路監控
QRadar 網路洞察、QRadar 事件取證
要求
此認證需要一門考試。… Continue reading
端側大語言模型原理與應用
原创 twt社区
【作者】李登昊,某金融單位人工智慧工程師,長期從事金融領域人工智慧服務落地應用工作,曾負責建置雲端自然語言處理模式服務系統,服務使用者超三十萬人;參與研發大模式智慧產品,對 大模型推理服務性能最佳化及RAG、Agent等技術有深入研究。
一、引言
隨著大語言模式的快速發展,不同場景對大語言模式的需求差異日益顯現。 特別是對手機、PC以及汽車等終端智慧系統來說,出於對輕量敏捷、安全穩定和成本等方面的考慮,傳統的雲端大語言模型服務並不能完全滿足需求。 因此,端側大模型在這些領域的熱度日益提升,逐漸成為新的產業趨勢。 本文旨在透過介紹端側大語言模型的發展現狀、關鍵技術和應用場景,幫助讀者了解端側大語言模型的技術路線和發展趨勢。
二、端側大語言模型概述
2.1 大語言模型概述
大語言模型(Large Language Model,LLM)是一種人工智慧模型,旨在理解和產生自然語言。 基於深度神經網路的自然語言模型架構演進經歷了早期的循環神經網路(Recurrent Neural Networks,RNN)和長短期記憶(Long Short Term Memory,LSTM)時代,在Transformer架構出現後,其迅速成為語言模型的 主流架構。 在基於Transformer的架構中,早期以Google BERT為代表的Encoder-only架構在各項下游任務上表現優於Encoder-Decoder架構和Decoder-only架構。 而隨著算力的不斷發展,模型規模不斷提升,自然語言生成能力也迎來湧現時刻,以OpenAI GPT系列模型為代表的Decoder-only架構在近兩年成為大語言模型主流技術架構。 與傳統的語言模型相比,大語言模型的特點是規模龐大,包含數十億甚至上千億參數,在TB級別的大量文本資料上進行訓練,這使得它們掌握了自然語言中的複雜模式, 產生湧現能力,可執行包括文本總結、翻譯、分類等廣泛的任務。
在大語言模式發展的早期,其應用普遍以呼叫雲端部署的模型服務介面形式進行。 而隨著其在各類自然語言處理任務中應用範圍的擴展,面向雲端服務介面僅透過設計提示詞(Prompt)對介面進行包裝的模式逐漸無法滿足企業級應用對場景複雜度和響應時效性不斷 增長的要求。 因而端側大模型的受重視程度逐漸提升,AIPC、AI手機和AI車機等軟硬體結合的端側大模型落地應用案例如雨後春筍般發布,又進一步推動端側軟硬體技術的快速發展,形成 新時代的適用於大模型的摩爾定律。
2.2 軟硬體技術現狀
由於大語言模型龐大的體量,適用於傳統深度學習的通用軟硬體技術在性能方面遭遇了前所未有的挑戰。 因而多種軟硬體技術被提出,以優化大語言模型的訓練、微調和推理階段的速度和資源消耗,降低其研究和應用的門檻。
由於訓練所需的巨量算力資源,僅有少數企業和機構會選擇從頭訓練大模型,因而相關技術開源程度和通用程度低。 主流大模型訓練,算力硬體通常為Nvidia A100或更先進的H100和B100 GPU;而Nvidia Megatron和Microsoft Deepspeed為大模型訓練提供了整合先進最佳化技術的軟體支援。 在國內,華為昇騰910 NPU同樣支援大規模算力集群的建構與調度,被廣泛用於大語言模型的訓練;而國內GPGPU方向的領頭羊海光與多數企業的ASIC技術路線不同,推出的深 算二號DCU採用「類CUDA」通用平行運算架構,能夠較好地適應並適應國際主流商業運算軟體和人工智慧軟體,產品效能達到國內領先。
相較之下,利用LoRA等參數高效演算法,基於開源大模型底座進行微調所需算力接近傳統深度學習任務,因而得以在更多企業和機構中進行。 主流的深度學習框架如Meta Pytorch、Google TensorFlow和國內的華為昇思、百度飛槳、阿里MNN等都為大模型的微調技術提供了開箱即用的支援。
但對於端側而言,軟硬體技術的核心目標在於為使用者提供大語言模型推理服務,訓練與微調並非端側需要考慮的任務。 在推理方面,Intel在進一步提升CPU產品對大模型的支援的同時,推出NPU(Neural Processing Unit)與原有CPU和整合GPU有機結合來應對AIPC時代的到來,Nvidia在牢牢把控雲端算力 先進地位的同時,也推出了在消費級GPU上的大模型應用。 而在AI手機、AI車機方面,高通、聯發科等頭公司也與手機、汽車廠商共同發表原生支援大模型能力的新產品。 國內以華為代表的端側技術供應商也緊跟國際先進企業步伐,在新一代產品中為用戶帶來大模型能力。
開發者,Intel BigDL和OpenVINO提供了在AIPC上運行大模型的完整框架;MLC(Machine Learning… Continue reading
思科認證300-710考試詳情指南
思科認證300-710考試詳情指南
一、認證背景
300-710考試是思科專業認證的一部分,是一項專業認證,旨在驗證考生在網絡安全方面的專業知識和技術。該認證主要針對網絡工程師,系統工程師,網絡管理員等IT專業人士。在當今信息安全越來越受到重視的背景下,取得這個認證可以為網絡專業人士開啟更多的職業發展機會,證書的獲得能夠證明他們在網絡安全領域具有高級的專業技能。
二、考試內容
300-710考試的內容主要涵蓋以下幾個部分:
防火牆技術:這部分考試內容包括了解和配置思科的防火牆設備,管理和監控防火牆的運行等。這需要考生瞭解防火牆的工作原理,並熟悉思科的防火牆設備和管理軟體。
入侵防護系統:這部分考試內容包括了解和配置思科的入侵防護系統,管理和監控系統的運行等。這需要考生瞭解入侵防護系統的工作原理,並熟悉思科的入侵防護設備和管理軟體。
網絡安全策略:這部分考試內容包括設計和實施網絡安全策略,管理和評估策略的效果等。這需要考生能夠瞭解和應用各種網絡安全策略,並能夠評估策略的效果。
高級網絡安全技術:這部分考試內容包括VPN,安全協議,加密技術等高級網絡安全技術的理解和應用。這需要考生對這些技術有深入的理解,並能夠在實際環境中應用這些技術。
三、複習方法及重點
為了通過300-710考試,考生需要專注於以下幾個重點:
理解和應用防火牆技術:考生需要對思科的防火牆設備和技術有深入的理解,並能在實際環境中應用這些技術。這需要在實際的設備或模擬環境中進行大量的實踐。
掌握入侵防護系統:考生需要瞭解思科的入侵防護系統的工作原理,並能夠配置和管理這些系統。這需要在實際的設備或模擬環境中進行大量的實踐。
設計和實施網絡安全策略:考生需要能夠根據組織的需求設計和實施有效的網絡安全策略。這需要考生對網絡安全的最佳實踐有深入的理解,並能夠結合組織的具體情況制定合適的策略。
了解高級網絡安全技術:考生需要了解並能夠應用各種高級網絡安全技術,如VPN,安全協議,加密技術等。這需要考生對這些技術有深入的理解,並能夠在實際環境中應用這些技術。
四、官方考試費
考試的費用因地區和考試類型而異,具體的費用應在思科的官方網站上查詢。考試費用通常包括考試本身的費用和可能的註冊費。此外,考生還需要考慮到準備考試的其他成本,如購買參考書籍,參加培訓課程等。
五、考試時間
考試時間通常由思科公司決定,並會在考試公告中公布。考試時間可能會根據考試的難度和內容的範疇而變化。考生在考試前需要確認考試的具體時間,並確保在考試當天有充足的時間參加考試。
六、考試政策
思科公司有一套明確的考試政策,包括考試規則,考試程序,以及其他與考試相關的政策。考生在報名參加考試前需要仔細閱讀和理解這些政策,以確保他們在考試過程中能夠遵守這些規則,並避免出現任何問題。
七、考試中心和預約流程
考試通常在思科認證的考試中心進行。這些考試中心遍布全球,提供了一個安靜,舒適的環境,讓考生可以專心參加考試。要預約考試,考生需要先註冊一個帳號,然後選擇考試,選擇考試中心,並支付考試費用。在考試當天,考生需要帶上有效的身份證件,按時到達考試中心。
八、提供相似樣題
為了幫助考生更好地準備考試,思科在其官方網站上提供了一些考試樣題。這些樣題可以幫助考生了解考試的格式和題型,並可以用來測試和提高自己的知識和技能。考生可以利用這些樣題來評估自己的學習進度,並確定是否需要進一步的學習或實踐。
以上就是思科認證300-710考試的詳細資訊,希望這些資訊能夠幫助您更好的準備考試。無論您是剛剛開始您的IT職業生涯,還是已經在此領域工作多年,這個考試都是驗證您技術能力和知識的絕佳方式。另外,獲得這個認證將是您職業生涯的一個重要里程碑,它將證明您的專業技能,並可能為您帶來更多的職業發展機會。… Continue reading
比爾・蓋茲:AI 有風險,但是可控
为开发者服务的 21CTO
導讀:蓋茲最近的說法,AI存在著風險,但整體可控。
北美當地時間 7 月 11 日,比爾・蓋茲(Bill Gates)在個人部落格中發表了一篇文章,他闡述了對當下人工智慧發展的一些看法。
比爾・蓋茲:AI 有風險,但是可控

图片来源:gatesnotes 站点
這篇部落格文章題為《AI 確實存在風險,但是可控》,蓋茲在其中提到了當前 AI 具有五大風險。
概要如下:
AI 產生的錯誤訊息、深度偽造訊息,可能被用來欺騙民眾;
AI 可以自動檢索電腦系統中的漏洞,這大大增加網路攻擊的風險;
AI 可能會搶走人們的工作;
AI 系統會編造訊息,並表現出偏見;
使用 AI 工具可能意味著學生無法學習基本技能,如論文寫作,同時也擴大教育成就差距。
比爾・蓋茲也強調說,這並不是新技術首次導致人力資源市場發生巨變,AI 帶來的影響雖不及工業革命那般巨大,但肯定比得上 PC 問世所帶來的影響。
同時,比爾・蓋茨指出,“我們有更多理由樂觀地認為,人類可在處理 AI 風險時,最大限度地發揮自身優勢,但我們需要快速行動”,他提出如下幾點建議:
各國政府需累積 AI 的知識,以便推出應對 AI 的相關法律法規,如法律需明確哪些使用「深度偽造」的情形是合法的或違法的。
私人 AI 企業需保障自身能夠安全、負責地開展工作,包括保護隱私、確保 AI 模型符合人類價值觀、最大限度減少偏見、使技術盡可能受惠於大眾且防止被犯罪分子利用。
最後,比爾蓋茲鼓勵大家盡可能關注… Continue reading
防火牆術語
防火牆術語
01 網關
在兩個設備之間提供轉發服務的系統。
網關是互聯網應用程式在兩台主機之間處理流量的防火牆。
這個術語是非常常見的。
02 DMZ非軍事化區
為了配置管理方便,內部網路中需要向外提供服務的伺服器往往放在一個單獨的網段,這個網段便是非軍事化區。
防火牆一般配備三塊網卡,配置時一般分別分別連接內部網,Internet和DMZ。
網路中的資料由一個個資料包組成,防火牆對每個資料包的處理要耗費資源。
吞吐量是指在不丟包的情況下單位時間內通過防火牆的資料包數量。 這是測量防火牆性能的重要指標。
04 最大連線數
和吞吐量一樣,數字越大越好。
但是最大連線數更貼近實際網路情況,網路中大多數連線是指所建立的一個虛擬通道。
防火牆對每個連線的處理也好耗費資源,因此最大連線數成為考驗防火牆這方面能力的指標。
封包轉送率:是指在所有安全規則配置正確的情況下,防火牆對資料流量的處理速度。
05 SSL
SSL(Secure Sockets Layer)是由 Netscape 公司開發的一套Internet 資料安全協定。
它已被廣泛地用於網頁瀏覽器與伺服器之間的身份認證和加密資料傳輸SSL協定位於TCP/IP 協定與各種應用層協定之間,為資料通訊提供安全支援。
06 網路位址轉換
網路位址轉換(NAT)是一種將一個IP位址域對應到另一個IP 位址域技術,從而為終端主機提供透明路由。
NAT包括靜態網路位址轉換、動態網路位址轉換、網路位址及連接埠轉換、動態網路位址及連接埠轉換、連接埠對映等。
NAT常用於私有位址域與公用位址域的轉換以解決IP位址匱乏問題。
在防火牆上實現NAT後,可以隱藏受保護網路的內部拓樸結構,在一定程度上提高網路的安全性。
如果反向NAT提供動態網路位址及連接埠轉換功能,還可實現負載平衡等功能。
07 堡壘主機
一種被強化的可以防禦進攻的計算機,被暴露於因特網之上,作為進入內部網絡的一個檢查點,以達到把整個網絡的安全問題集中在某個主機上解決,從而省時省力,不用考慮 其它主機的安全的目的。
05.硬體防火牆和軟體… Continue reading
企業傳統資料庫遷移到國產或開源資料庫的六個重要階段
韩锋频道 twt企业IT社区
【導讀】越來越多的企業正面臨將傳統資料庫遷移到開源或新型商業產品上,本文整理了在此過程中,困擾企業的一些常見問題,結合整個遷移過程中的六個階段進行說明, 這是一篇優秀的實用文章。 希望對讀者在資料庫選用及評估資料庫遷移風險等方面有所啟發。
【作者】韓鋒,CCIA(中國電腦協會)常務理事,前Oracle ACE,騰訊TVP,阿里雲MVP,dbaplus等多家社群創辦人或專家團成員。 有著豐富的一線資料庫架構、軟體研發、產品設計、團隊管理經驗。 曾擔任多家公司首席DBA、資料庫架構師等職。 在雲端、電商、金融、網際網路等產業均有涉獵,精通多種關聯式資料庫,對NoSQL及大數據相關技術也有涉獵,實務經驗豐富。 曾著有資料庫相關著作《SQL優化最佳實務》、《資料庫高效優化》。
隨著近年來資料庫的變化,正有越來越多的企業面臨將傳統資料庫遷移到開源或新型商業產品。 在這過程中,會面臨諸多問題。 這裡就將常見的一些問題整理出來,希望能夠在資料庫選型及評估資料庫遷移風險等方面有所幫助。 為了描述清晰,我將整個遷移過程劃分為幾個階段,其中橙色標識工作為資料庫團隊來支援。 以下將就每個階段,詳細展開說明。
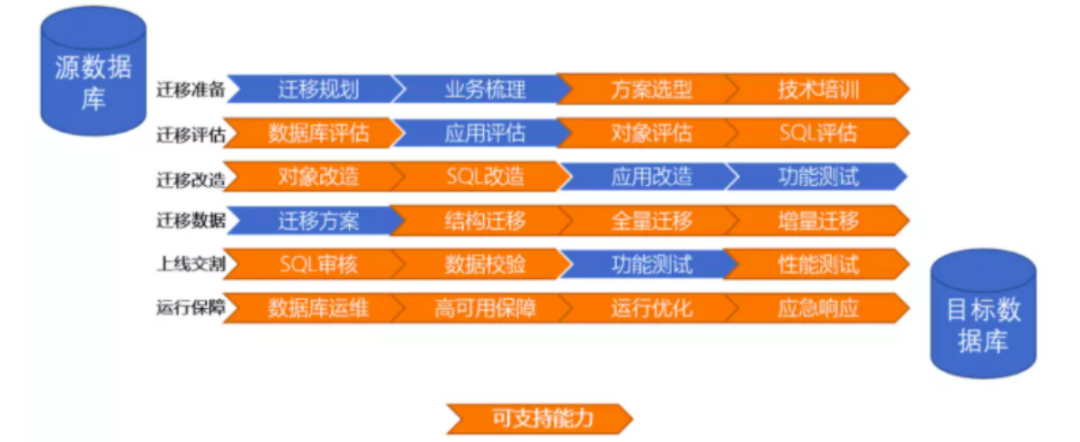
1. 階段:遷移準備
1) . 遷移規劃
在進行遷移之初,首先要對遷移工作做個整體規劃,並制定好對應的原則方針。 例如明確遷移範圍、遷移方式、是否可停機、窗口期等等。 這些資訊是作為後續遷移的指導原則,遷移方案的發展很多需依靠這項規劃。 要避免出現快要遷移,發現預期不符合要求的狀況,提前做好必要的規劃。 此外,除技術因素外,其他如組織、管理、資源等,也在此階段一併考慮。 遷移是個很複雜的過程,涉及的各個面向很多,盡量在專案之初就有個全面的掌握。
2) . 業務梳理
要完成資料庫遷移,上層的業務系統也是需要考慮的,甚至在某種程度講,配套的應用遷移更加重要,在後續的遷移過程中佔比也更高、難度也更大。 因此,在遷移準備階段,就對涉及的業務有個全面的梳理非常有必要。 這裡需要梳理的訊息,非常廣泛。 包括但不限於對業務系統涉及的軟硬體環境、與資料庫互動、業務系統間呼叫關係等。 後續在做應用系統改造規劃中,上述資訊非常重要,其有助於評估工作困難、工作量等。 這裡舉個例子,某系統之前使用Oracle,開發採用C語言,在遷移到某國產庫時發現,資料庫不支援C driver,好不尷尬。
3) . 方案選型
在做好業務整理後,就是資料庫選型。 這過程也是遷移準備階段比較耗時的工作。 如何從眾多的資料庫產品中選擇一款符合自己要求的,要考慮的因素很多。 比較建議的做法,是在公司內部之前就制定出推薦的方案矩陣,根據對資料庫能力需求、系統重要程度等,制定一個產品選型矩陣。 如果前期有這個基礎,就比較簡單,只要按圖索驥即可。 如果沒有的話,需要從頭完成一連串的工作,包括初步研究、技術評估、資料庫評測(功能、非功能、業務等)、適配性評估等。 這裡強調一個原則就是盡量在方案選型中保持最大的自由度,也就是不綁定單一廠商,隨時保持可替換能力。 因此在方案選用中,不能本著業務少改造、遷移最簡單、成本最低的方案,而是應選擇長期可替代的原則。 建議的做法是選擇相容通用協定的產品,盡量弱化資料庫端能力,選擇使用標準資料庫功能的產品最好。
4) . 技術培訓… Continue reading