

思享家丨思科 Silicon One 以一頂三,構建靈活高效的 AI 網絡
思科聯天下
作者:蒋星
思科首席架构师,
作者:李婷婷
思科资深系统架构师
隨著 GPT,Stable Diffusion 等各種人工智能 (AI) 大模型業務的爆炸式增長, 國內外雲和互聯網企業正在掀起一場構建AI算力的新型競賽。然而單純通過堆砌更多的 GPU 並不能獲得算力的線性提升,因為面向雲計算的傳統以太網絡正在成為大規模 AI GPU 間通訊的瓶頸。隨著新一代 GPU 算力的提升,每顆 GPU 能夠產生高達 400G 的峰值通訊流量,而大模型 AI 訓練任務經常會將數據或模型分配到成千上萬的 GPU 中同步並行處理,AI 任務的定期數據分發和數據同步的通訊特性對連接 AI 服務器的網絡提出全新的要求:超高速,超大吞吐量,低長尾時延,高可靠和盡可能高的效率。

▲圖 1. AI 數據中心業務與網絡的發展趨勢
為了解決 AI 網絡通訊的困境,目前行業中存在四種獨特 AI 網絡架構:InfiniBand、以太網、增強以太網和完全可調度的分佈式以太網(Distributed Switch Fabric, DSF)。每種技術都有優點和缺點,比如 InfiniBand 主要面向 HPC 單任務應用場景設計,提供無損傳送和低時延能力,但用於多任務/多租戶的 AI 場景時則表現欠佳,另外昂貴的線纜與配件價格、有限的生態系統和產品更新迭代的速度,都令業界多一層考量。以太網由於生態、成本和快速技術迭代正在成為 AI 網絡備受關注的技術。根據 JP Morgan 市場預測,到 2027 年基於以太網技術的 AI 網絡將會佔據 75% 的市場份額。思科看到 AI 網絡行業正在朝著多個增強型 AI 以太網方向發展,以滿足 AI 多樣化的業務需求。
市場上其他大多數芯片架構都將客戶鎖定在一個狹窄的部署模型中(上述模型中四選一),迫使客戶在早期購買芯片或設備時就需要做出 AI 網絡技術路線的決策,並且在未來很難進行更改或升級,這大大地限制了 AI 網絡架構未來演進和升級的靈活性。
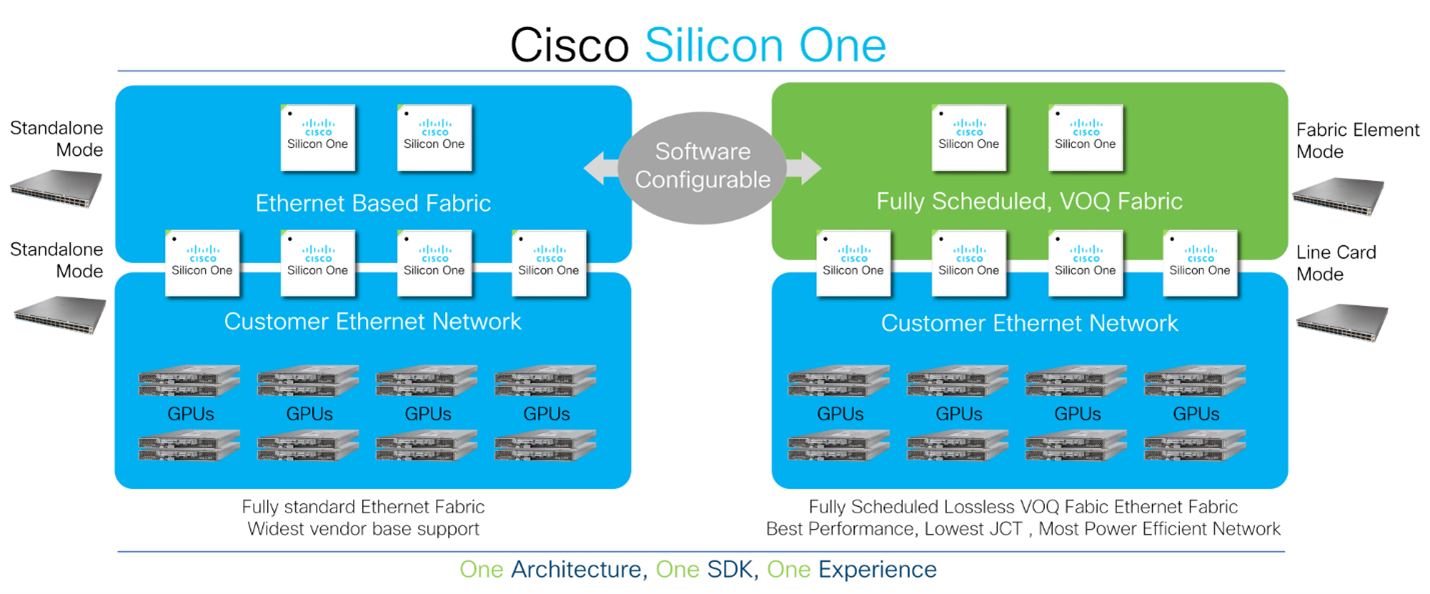
▲圖 2. Cisco Silicon One 的靈活性
思科正在通過 Silicon One 芯片和網絡架構的創新,幫助客戶構建面向未來的高性能、可擴展且高效率的新一代 AI 數據中心網絡。 Cisco Silicon One 的統一芯片架構優點使得客戶可以通過軟件定義的方式將 AI 數據中心網絡配置成為三種模式:
1. 基於 ECMP 的標準以太網
2. 增強以太網
3. 全調度分佈交換(Distributed Switch Fabric, DSF)以太網(VOQ+逐包負載分擔)
▲圖 3. AI/ML 網絡解決方案選項
由於 Cisco Silicon One 可以靈活支持多種架構,並在每種模式下提供同類最佳的特性,客戶不需要在網絡建設的第一天就固化技術演進路線圖,可以根據業務的不斷發展採集網絡傳輸的實際數據,並做出數據驅動的技術決策。而 Silicon One 的 P4 可編性程架構通過軟件迭代持續支持未來不同 AI 模型業務的需求與發展。
●不同 AI 網絡架構的性能分析
與傳統數據中心應用相比,AI 訓練集群具有獨特的流量模型。 GPU 可以產生大量的數據並跑滿高帶寬鏈路,同時因為每個 GPU 要將計算結果發送給其他 GPU 成員,這種數據傳輸模式稱為 “All to All & All Reduce” 集約通訊。在集約通訊結束時,所有 GPU 的模型權重、梯度、訓練數據都需要同步到最新的狀態。這種同步啟動和停止的工作模式使得網絡長尾通訊時延(最慢通訊路徑)變得至關重要。由於等待部分 GPU 通過網絡的最慢路徑完成同步,這將導致其他 GPU 暫停工作並閒置。在 AI 的應用場景中,普遍採用 “作業完成時間 (JCT)” 來衡量網絡的性能,以確保所有節點和路徑都運行良好。
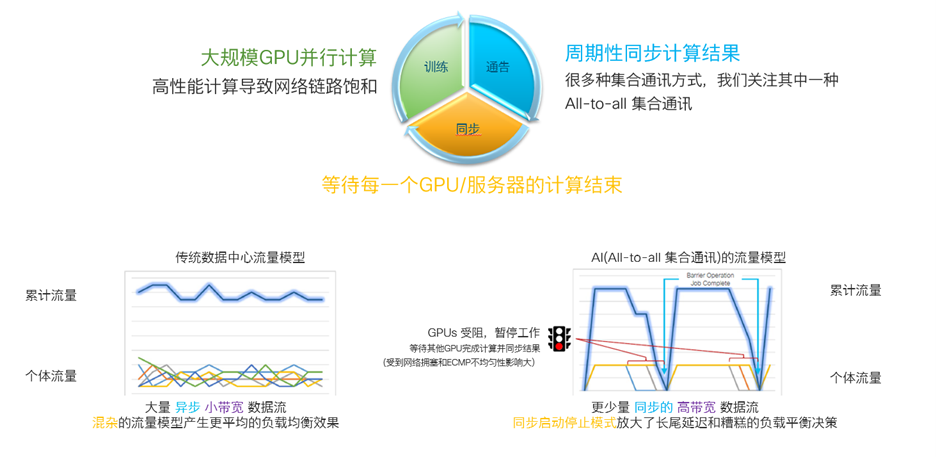
▲圖 4. AI/ML 計算和同步過程
為了分析不同網絡架構對 AI 任務的執行效能的影響,思科創建了一個小型訓練集群模型,其中包含 256 個 GPU、八個架頂 (TOR) 交換機和四個主幹(SPINE)交換機。然後我們使用一個 all-to-all 集約通訊來傳輸 64MB 的集約數據,通過改變網絡上同時運行的 AI 任務數量,以及 TOR 到 SPINE 設備互聯鏈路帶寬的加速比來測量最終 AI 作業完成時間(JCT)以考察不同網絡架構的性能差異。
這項研究的結果是戲劇性的。
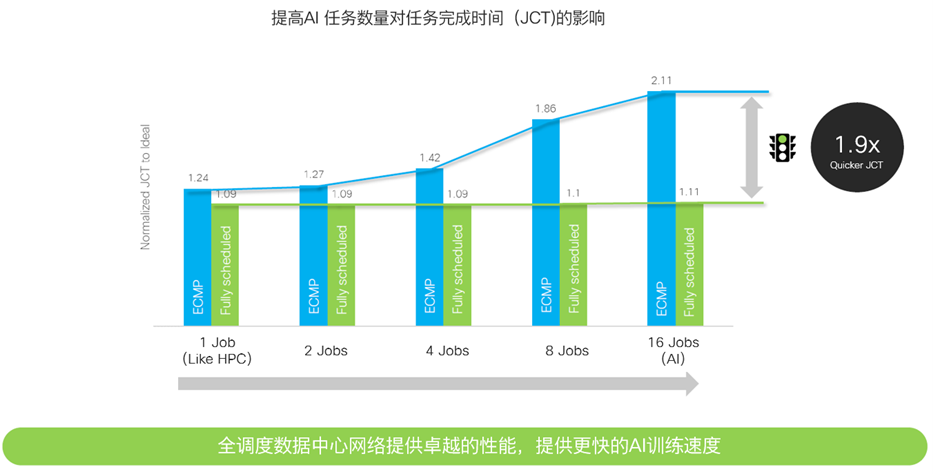
▲圖 5. ECMP 以太網架構與 DSF 架構的 AI 作業完成時間(JCT)
與專為單一作業而設計的 HPC 任務不同,大型 AI/ML 訓練集群旨在同時運行多個作業,類似於當今互聯網和雲服務商數據中心的情況。隨著 AI 作業數量的增加,使用傳統 ECMP 以太網方案(藍色)和使用 DSF 方案(綠色)的 AI 作業完成時間差異變得更加明顯。在 256 個 GPU 上運行 16 個作業,一個 DSF 的 AI 作業完成時間比傳統 ECMP 標準以太網快 1.9 倍。
另一方面,思科從流控的角度研究不同架構對AI任務完成時間的影響,通過監測從網絡發送到 GPU 的背壓流量控制 (PFC) 報文的數量,思科發現在 ECMP 以太網架構中有 5% 的 GPU 由於網絡 ECMP 哈希極化等原因導致網絡通訊產生高 1.25 毫秒的長尾時延,這拖慢了其餘 95% 的 GPU的運行效率。與之相對應,DSF 網絡架構則提供了完全無阻塞的通訊性能,並且網絡不會暫停 GPU 發送流量。
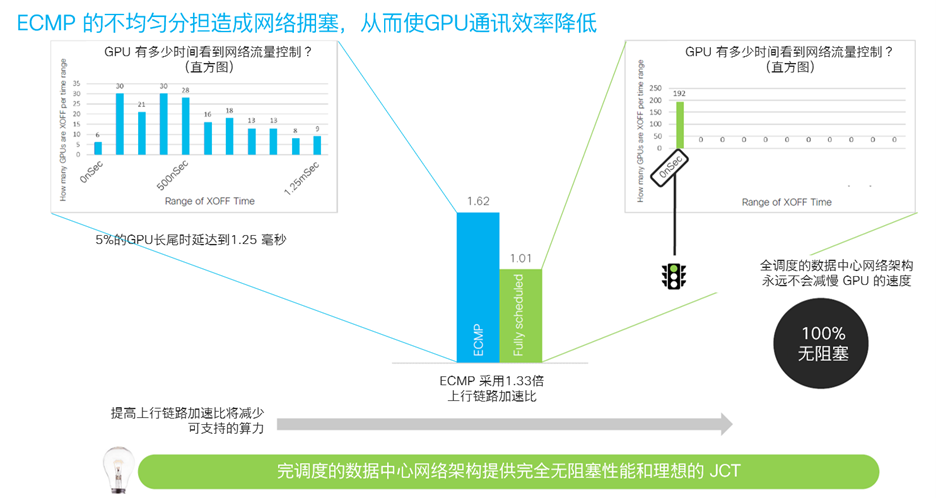
▲圖 6. ECMP 以太網與 DSF 網絡對 GPU 流量控制的影響
這意味著對於相同的物理網絡,採用 DSF 架構可連接的 GPU 數量是 ECMP 以太網架構的兩倍。這大大地提高了網絡的效率、降低了成本。
除了以上兩種網絡架構之外,思科 Silicon One 同樣可以支持遙測(INT)增強的 AI 以太網架構, 這種架構的目標是通過在數據包內部插入沿途網絡設備的數據擁塞位置與程度的信息,向收發側的服務器或採集器節點發出業務路徑、擁塞信號,從而可以快速、主動改進負載均衡決策來提高標準以太網 ECMP 的吞吐性能,並降低時延,避免丟包。
上述三種網絡架構採用的各種技術的相對優點因客戶而異,並且可能會隨著時間和不同業務需求的變化發生改變。
●如何為 AI 選擇最合適的網絡架構?

▲圖 7. 使用 Cisco Silicon One 構建您的 AI 網絡
想要享受以太網的成熟生態系統、開放標準和低成本的客戶應該為 AI/ML 網絡部署 ECMP 以太網架構。面向未來,他們可以通過增加遙測(INT)和通過在基礎設施上仔細的規劃 AI 任務來均衡網絡負載,從而提高AI性能。
希望享受虛擬輸出隊列 (VOQ) 的完全無阻塞性能、完全可調度、逐包負載均衡等創新解決方案的客戶,應該為 AI 部署 DSF 架構,這將使 AI 工作完成時間縮短 1.9 倍。 DSF 架構也非常適合希望通過精簡網絡組件來節省成本和功耗的客戶,精簡後的網絡仍能實現與以太網相同的性能,或者相同網絡規模支持的 GPU 計算量增加 1 倍。

▲圖 8. Cisco Silicon One 統一架構芯片體系
Cisco Silicon One 具有統一架構的獨特的優勢,以一頂三,可以為客戶提供具有融合架構和行業領先性能的解決方案。客戶不需要在網絡建設的第一天就固化技術演進路線圖,可以根據技術和業務的不斷發展做出靈活的決策。
Comments
Tell me what you're thinking...
and oh, if you want a pic to show with your comment, go get a gravatar!